公司要做一个搜索,数据量不大但是着急,引入ES就显得来不及了,于是决定就用mysql的全文索引原地实现,过程中踩了一些坑:
一开始是就是简单了使用了FULLTEXT全文索引 ,然后在搜索的时候发现结果十分的不尽人意,原来是MYSQL的FULLTEXT索引默认的分词策略的问题,中文全部按照一种分词方式来,也就是说 你要是不搜中文的全名,在自然语言模式下(IN NATURE LANGUAGE MODE) 根本搜不出来东西。
全文索引文档:https://dev.mysql.com/doc/refman/5.7/en/fulltext-search.html
但是在查阅文档的时候发现了ngram这个解释器,mysql自带的
ngram官方文档:https://dev.mysql.com/doc/refman/8.0/en/fulltext-search-ngram.html
因为都是已经存在了的表了 就直接Navicat或者DDL语句就可以新建,我依赖于图形工具,就直接新建了但是第一个坑就来了:
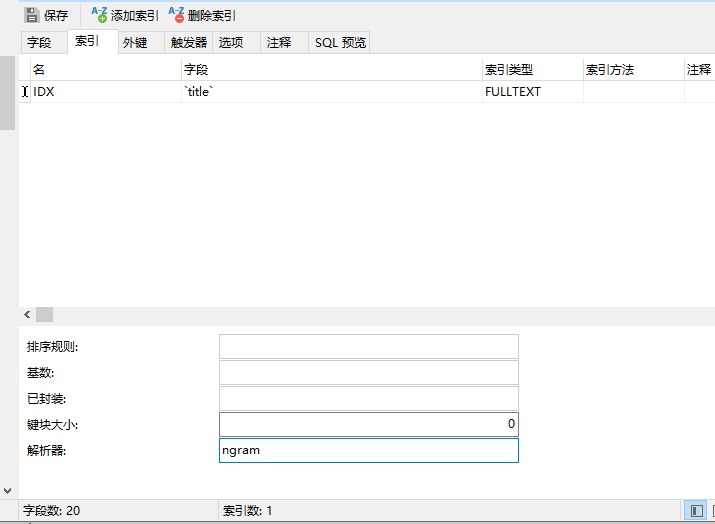
直接在原有的索引上进行的修改 保存之后没生效!!! 但是我不知道 展现出来的就还是搜索不出来结果,后来检查了一下才发现不能完全相信Navicat那就使用DDL语句呗 2号坑就来了,我用Navicat模拟了一下操作 生成了DDL语句如下(错误的那个):
错误DDL:
<del>ALTER TABLE <code>biz_shop_spu</code></del>
<del>DROP INDEX <code>IDX_NAME_FULLTEXT</code>,</del>
<del>ADD FULLTEXT INDEX <code>IDX_NAME_FULLTEXT</code>(<code>NAME</code>) WITH PARSER NGRAM;</del>
正确:
ALTER TABLE `biz_shop_spu`
DROP INDEX `IDX_NAME_FULLTEXT`;
ALTER TABLE `biz_shop_spu`
ADD FULLTEXT INDEX `IDX_NAME_FULLTEXT`(`NAME`) WITH PARSER NGRAM;
必须重新ALTER一下表 不然直接DROP旧索引插入索引的话 ,用FlyWay执行不会报错 但是还是没有使用ngram。
flyway执行结果图:

- 至此一个使用ngram作为解释器的全文类型的索引 就建立完成了,但是分词只会对新数据进行分词,导致使用全文索引搜不出来历史数据
需要显式的使用OPTIMIZE TABLE biz_shop_spu
这个是清理表碎片文件的命令 但是它也会重新更新索引的统计数据
ps:命令执行期间会锁表哦~
至此踩坑部分完毕
下面就是一些ngram的小技巧
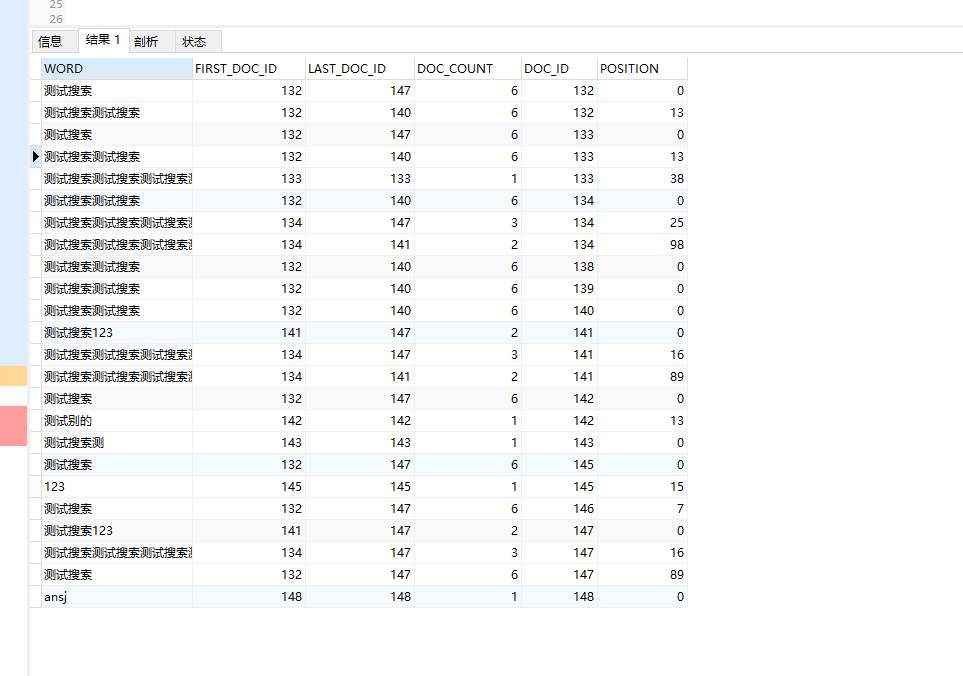
- 观察索引的分词:
如果使用了ngram就不用看这个SHOW VARIABLES LIKE '%ft%';了 而是看这个show variables like 'ngram_token_size%'; 默认是2
- 显式指定全文检索表源:
SET GLOBAL innodb_ft_aux_table="db_name/tableName" <code>搭配SELECT * FROM information_schema.innodb_ft_index_cache ORDER BY doc_id , position;可以看到哪些词在全文索引里面